Training Parameters for Deep Learning Models
The default training parameters for Deep Learning models should work well in most cases. However, you can edit the training parameters if your results are not satisfactory.
Right-click the Deep Learning model you need to edit on the Models tab and then choose Update Training Parameters in the pop-up menu to open the Training Parameters dialog, shown below.
Training Parameters dialog

The Training Parameters dialog includes three tabs — Settings, Advanced Settings, and Data Augmentation — as well as a number of options for applying and saving changes, which are described below.
Save as Defaults… Saves the current settings as the default values, which will be applied to new models.
Load Defaults… Restores the model settings to the last saved default values.
Reset Defaults… Resets all model settings to their original values.
Apply to… The Apply to options include the following:
- Current model only. If selected, all changes will be applied to the selected Deep Learning model only.
- All current deep models. If selected, all changes will be applied to all Deep Learning models in the current Segmentation Wizard session.
The following basic settings, which include patch size, stride ratio, and epochs number, as well as loss function and optimization algorithm, are available on the Settings tab.
|
|
Description |
|---|---|
|
Patch size |
During training, training data is split into smaller 2D data patches, which is defined by the 'Input (Patch) Size' parameter. For example, if you choose an Input (Patch) Size of 64, the Segmentation Wizard will cut the dataset into sub-sections of 64´64 pixels. These subsections will then be used as the training dataset. By subdividing images, each pass or 'epoch' should be faster and use less memory. |
|
Stride ratio |
The 'Stride to Input Ratio' specifies the overlap between adjacent patches. At a value of '1.0', there will be no overlap between patches and they will be extracted sequentially one after another. At a value of '0.5', there will be a 50% overlap. You should note that any value greater than '1.0' will result in gaps between data patches. |
|
Epochs number |
A single pass over all the data patches is called an 'epoch', and the number of epochs is controlled by the 'Epochs number' parameter. |
|
Loss function |
Loss functions, which are selectable in the drop-down menu, measure the error between the neural network's prediction and reality. The error is then used to update the model parameters. Refer to Loss Functions for Semantic Segmentation Models for additional information about the available loss functions. Note Go to www.tensorflow.org/api_docs/python/tf/keras/losses for additional information about the loss functions available in the Segmentation Wizard. |
|
Algorithm |
Optimization algorithms are used to update the parameters of the model so that prediction errors are minimized. Optimization is a procedure in which the gradient — the partial derivative of the loss function with respect to the network's parameters — is first computed and then the model weights are modified by a given step size in the direction opposite of the gradient until a local minimum is achieved. The Segmentation Wizard provides several optimization algorithms — Adadelta, Adagrad, Adam, Adamax, Nadam, RMSProp, and SDG (Stochastic Gradient Descent) — which work well on different kinds of problems. Refer to Optimization Algorithm Parameters for additional information about the available optimization algorithms and editable settings. Note You can find more information about optimization algorithms at www.tensorflow.org/api_docs/python/tf/keras/optimizers. You can also refer to the publication Demystifying Optimizations for Machine Learning (towardsdatascience.com/demystifying-optimizations-for-machine-learning-c6c6405d3eea). |
The following advanced settings, which let you set learning rate patience and cooldown as a fraction of the available training data available, as well as set early stopping patience, are available on the Advanced Settings tab.
Advanced Settings tab

You should note the following whenever you edit the ‘Reduce learning rate on plateau’ and ‘Early stopping’ settings:
- Training voxels count will be shown as a tooltip whenever you hover over the training voxel count text, as shown below.
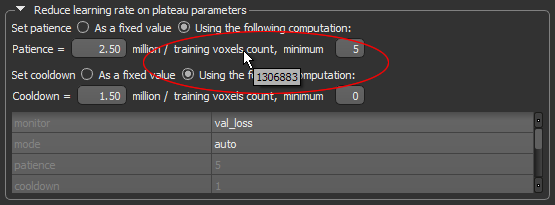
- With the ‘As a fixed value’ option checked, the computation section will be disabled and the behavior will be “normal”.
- With the ‘Using the following computation’ option checked, the 'patience' value in table will not be editable, but will be updated with the calculation result.
The following Data Augmentation settings, which let you set compensate small training sets by simulating more data, are available on the Data Augmentation tab.
Data Augmentation tab
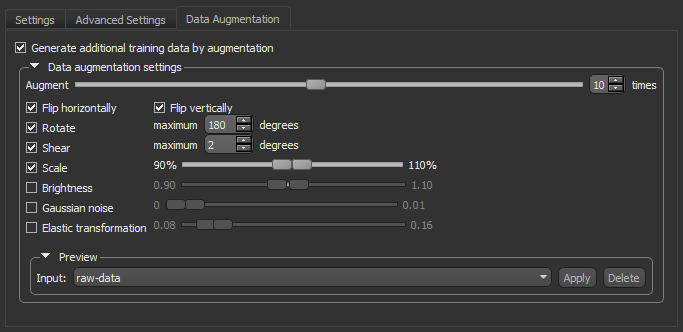
The performance of Deep Learning models often improve with the amount of data available, particularly the ability of models to generalize what they have learned to new images. A common way to compensate small training sets is to use data augmentation. If selected, different transformations will be applied to simulate more data than is actually available. Images may be flipped vertically or horizontally, rotated, sheared, or scaled. As such, specific data augmentation options should be chosen within the context of the training dataset. Refer to Data Augmentation Settings for information about modifying the data augmentation settings.